Techipe.Info | Tech Tips Enhancing Your Digital Experience
Discover the best tech tips and tricks
Home
Information
Technology
Lifestyle
Online Earning
Android Tips
Tech News
Empire Sound & Security Car Audio Window Tinting: The Ultimate Car Upgrade
3 Best Email Marketing Services Lookinglion: Boost Your Email Marketing Success
Pubg 1.3 Apk Download Without Vpn Creativepavan: Unlock the Power Zone
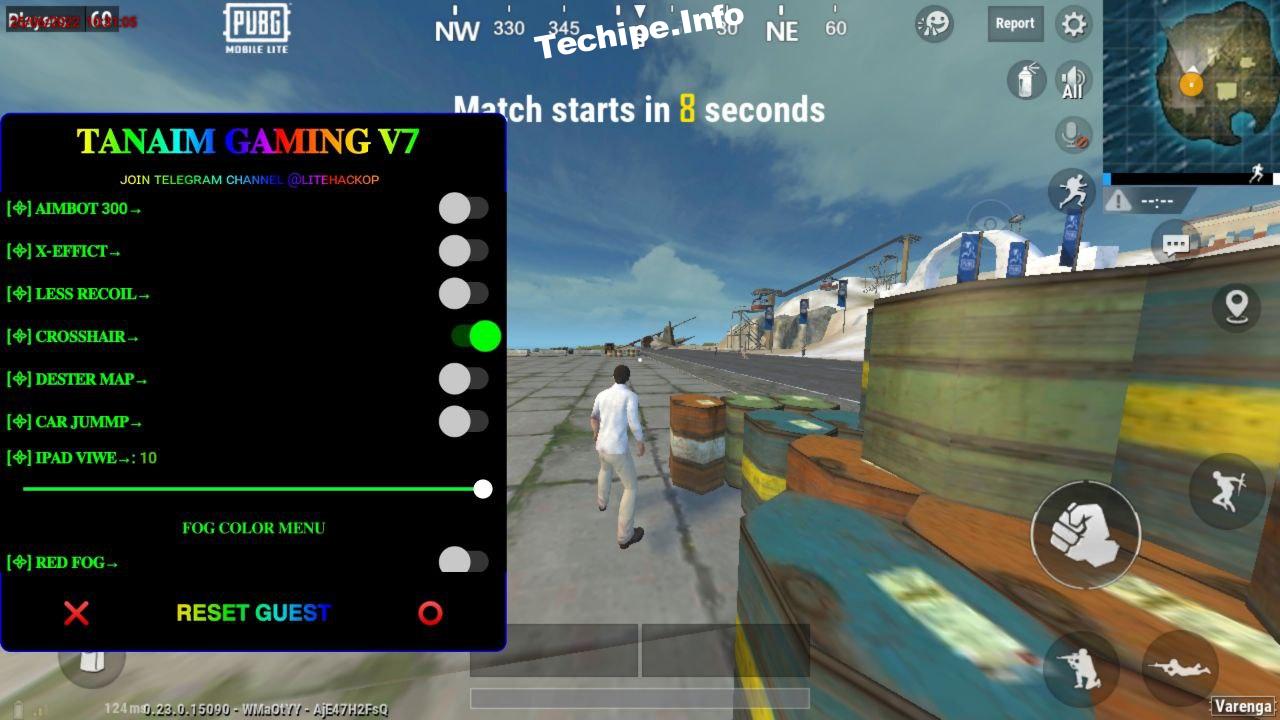
Pubg Mobile Lite Hack Unlimited Health Download: Gain Invincible Power
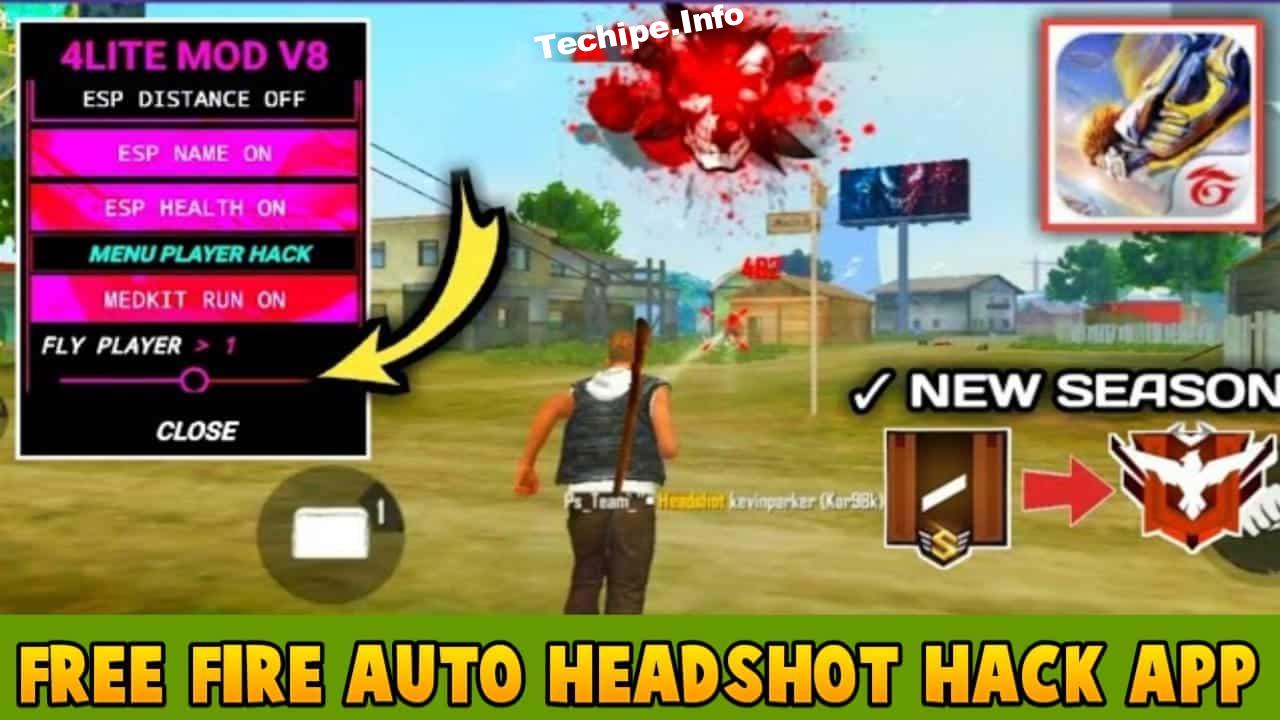
Appsmob Info Free Fire Hack: Unlock Ultimate Power
Pubg Mobile Lite Bc Generator: Boost Your Game with Unlimited BC!
Free Fire Unlimited Diamonds Cookole : The Ultimate Hack to Dominate the Game
Ai Cloth Remover : Unveiling the Power of AI
1 Hour No Copyright Music Download Free : Unleash the Power of Royalty-Free Melodies
Alternative to Remini App
1
2
…
15